題名:ネットワークについて
日付:1999/7/13
この文章について | ネットワークの動作概要 | Physical Layer:物理層 | Media Access Control SubLayer | Logical Link Sublayer | Network Layer | Transport Layer
Logical Link Sub layerさて、Data Link Layerを二つのサブレイヤーに分ければ、残るのは上位のLogical Link Sub Layerである。媒体をどう共用するか、というのはMAC Sublayerまでで話したついた、と考えるとこの層がやることは「できる限り」同一の媒体で接続された2点の間でエラーがない通信を実現することである。
さて、ここまで散々焦らしてきたLogical Link Control Layerの機能について書いてみよう。このLayerの基本機能は以下の通りである。
・ 隣接したシステムの間でのエラーのないフレームの伝送を行なう。そして上位レイヤーであるところのNetwork Layerへのサービスの提供をする。
ここで言うサービスとは以下の通り。
・ Connection Oriented(指向)のサービス:エラーなし、順序に従ったデータの伝送・ Acknowledge付きのConnection -less サービス
・ Acknowledge 無しのConnection -lessサービス
ここでいきなり登場したいくつかの呪文について以下に述べる。
まず基本機能の1番めのうち「隣接した」という表現の意味するところである。ここではその下のLayerすなわちMAC Sublayerを見たときに隣接している、という意味にとる。なぜこんな事を書くかといえば、これから記述するこのLLCの技術というのはこの「隣接した」の定義さえ変えてしまえばもっと上位のレイヤーでも使用できるからである。このことについてはいつの日か述べる機会もあるだろう。
次の呪文は「フレーム」だ。とはいっても既にMac Layerでフレームという言葉を使用している。ここでは以下の定義を用いる。
「構造の無い”Bit pipe"にデータの区切りをつけるために使用されるもの」
これでは何のことかわからないかもしれない。日本語で「わく」といったほうがイメージはすっきりするかもしれない。つまるところは伝送しようとするデータにはめられた一定のフォーマットの「わく」である。
これがなぜ必要になるかというとつまるところデータをある程度の単位に区切ることが、これから説明するところの「エラーのないデータ転送」を実施する上で必須となるからだ。
実際の通信回線ではエラーは不可避だから、「エラーのないデータ転送」とは「エラーがでたらそれを送り直すなどして補正する」ことでしかない。となれば、なんらかの単位で区切っておかないと「3番目と5番目と8番目のデータを送り直せ」ということができない。
さて、最後の(といってもこの文章のなかで最後ではないが)呪文、Connection-orientedとConnectionless, それにAcknowledgeである。
Connection-orientedというのはその名の通り、まずデータを送受信するまえに確たるデータの流れを築いてしまう。その上でデータを送受する方法をいう。この方法をとった場合にはデータのエラーは少なく、かつ送ったデータはそのままの順番で受け取られることが期待される。
Connection-lessとなるとそうはいかない。送信者と受信者はお互いまったく相手の都合だのタイミングだのに関係なくデータを送信する。したがってタイミングはあわないし、おまけに送った順番どおりで受信される、という保証も無い。
それに関連してでてくるのがAcknowledgeである。(「確認通知」とでも訳してみようか)Connection-lessはかくのとおり信頼のおけない通信形態であるからして、フレームごとに「ちゃんとうけとったよ」という確認を通知する必要がある。これがAcknowledgeである。
さて、こう書いてくると、「Connection-less- Unacknowledgedってのは誤りはどうしてくれるんだ」と思うかもしれない。まったくそのとおりでこの方式はDLC Layerでは誤りを制御しない。もし発生すれば「あとはよろしく」と上位レイヤーになげてしまうのだ。
そんな無責任な、と思うかもしれないが、こうすることにより、データの伝送自体は高速になる。データにエラーはあるかもしれないが、なんとしても高速に伝送したいデータには何があるか?たとえば音声データとかである。実のところ音声データのビットがところどころ違っていても誰も気がつかないであろう。逆に念入りなエラーチェックと再送など行い、会話の間に間が空いて聞こえれば昔の国際電話のように大変不自然なものになってしまう。
さて、かくのごとくの方式を用いてDLCではデータの伝送を行なう。とどこおりなくデータを伝送するためにはなんらかの制御が必要である。それらについて、一つは簡単に、もう一つは大変に長長しく記述する。
(1) Flow Control
データの伝送というのは双方のやりとりである。であるからして、相手が受け取れない以上の量のデータを送ったところでなんともならない。これは日常生活でも何かと起こり得る話だ。こちらがいきおいこんで立て板に水、という感じでまくしたてたところで、相手がしばしぼんやりした後に
「話が早すぎて何をいっているかわからん」
といわれてしまえばそれまでである。ここであなたが若々しく元気に満ちていれば「この○○」とか怒りだすか、あるいはまた一から説明ができるかもしれないが、私のように疲れ切った人間であれば、その場にへたりこんでそのままとなってしまうかもしれない。
さて、こうした事体をさけるための基本的な方法は、受け取り側から、情報を送信する側のスピードを制御できるようにすることである。もっと送れだの、ちょっとまてっだの。。
(2)Error Control
こちらは前述した「エラーのない伝送」を行うために必要なしかけだ。基本的な方法は以下の通りである。
・送り手側はパケットに或程度の冗長性を持たせる。具体的にはエラーがチェックできるようなデータを含める。(このエラーチェック用のデータは元のデータから生成されるものだから、確かに「或程度の冗長性」だ)
・受取手はエラーをチェックし、再送を要求する。
こういう概念的な言葉で書くと話は簡単だが、実際にはあれこれと面倒な話がついている。ではまずそもそも「エラー」とはどのようなものかから書いていく。
エラーとはすべからく通信上の間違いなのだが、ここではその「間違い」のあり方に応じて2種類に分類してみる。
一つはRandom bit errorと呼ばれるものであり、伝送されているビットがランダムに「間違う」ものだ。例えば
"0001000"
が
"0001100
となるような場合である。(5番目の1/0が反転している)
もう一種類はBurst Errorと呼ばれるものであり、もっと派手に「間違える」形態だ。パケットというのがデータをおくる単位である、という話しを前に書いたかどうか覚えていないが、Burst errorではパケットが半分0になっているとか、場合によってはパケットごとなくなってしまう場合もある。
さて、かくのごとくエラーを含んでいる通信回線では何がおこるだろうか。
前述したようにbit errorが起こればパケットの中身は正しくないかもしれない。またBurst Errorがおこればパケットそのものがなくなってしまうかもしれない。また場合によってはパケットが送信された順番どおりに受け取られないかもしれない。さらにはパケットが届く時間がまったく予期しない時間遅れて届くかもしれない。「もうこれ以上データはこないよね。では店じまい」と思った後にいきなりパケットが届くかもしれないのだ。
さて、かくのごとく信用のおけない通信回線(というか下位レイヤー)であってもDLCではエラーを検知し、ちゃんとした通信を行なわなければならないわけだ。そのためには何をすればよいか。
まず必要なのはエラーの検知である。これは簡単にはいかない。例えば事前に送り手と受け側で「このデータを送るからね」と合意ができていて、受取手は、受け取ったデータをそれと照らし合わせる、なんてことが可能であれば話しは簡単。しかしそんな合意が事前にできれば、わざわざデータを送る必要はないのだ。
(2-1)エラー検出方法
(2-1-1) Parity
さて、こうしたエラー検出には、そのための余分なデータを付加して送る、ということが行われる。例えばパリティというものだ。例えば7ビットのデータを送る際に、最後に1ビットある規則にしたがったビットを付加する。全体の1の数が常に偶数となる、といった規則だ。(これをeven parityと呼ぶ)
この規則に沿うと
"0000100"
というデータを送る際には、最後につけるビットは全体の1の数を偶数にするために
"00001001"となる。
うけとった側は受け取った8ビットのデータのうち、1の数をカウントする。それが例えば奇数であれば
「このデータは誤りがはいっている」
と判定できるわけだ。(エラーを検知した後どうするかはまた後で述べる)
さて、ここで説明した方法は、1ビットだけ付加するわけだし、その生成も簡単で検知も簡単。だから優れている、とは残念ながらならない。簡単な例だが、2bit以上エラーをおこせばそれで検知できない可能性がでてくる。(例えば受け取ったデータが"10011001"となってしまえば、「ああ。1の数は偶数ね」ということでこのチェックをとおってしまう)
(2-1-2) CRC
というわけで、世の中にはもっと強力にエラーを検知できる仕組みがある。Cyclic Redundancy Check、略称CRCである。エラーチェック用のデータを付与するという点では似ているが、生成の仕方、チェックの方法はもっと複雑だ。
思えば私がこのCRCなる言葉を目にしたのは入社2年目であった。パケット通信の標準なるものが存在する遠い昔から(あるいはそれを知らなかっただけかもしれないが)存在していたある特殊な通信系にかかわったからである。それを担当していた男はこのCRCが
「何千年に一度しか間違えない」
というのをやたらと自慢していた。
さて、このCRCである。私は今迄通算しておそらく3回はこの方法をどうやって計算するのか習ったきがする。そしてその度にきれいに忘れてしまっている。今回も
「何か別のページを見てほしい」
と逃げようかと思ったが。。そろそろCRCについて「新しく学ぶ」のもおしまいにしようと思い立った。幸いにしてよい例も見つかったので、(参考:http://www.cs.williams.edu/~tom/courses/336/outlines/lect7_2.html)ここで実例を交えながら方法について書いてみたい。
0)まず最初にいくつかの前提を置く。第一に取り扱うのは本来ビット列だが、これを多項式として扱う。例えば11010111であれば、これをX7+X6+X4+X2+X+1とみなす。(n桁目のビットが1になっていれば、Xのn-1乗の項があるとするわけだ)
そしてビットに関する処理をこの多項式に関する計算として扱う。
ここで「計算」とすんなり書いたが、ここで使う計算は通常われわれが慣れ親しんだものとはちょっと違っていて、modulo2と呼ばれる。ベースは2進法なのだが、この計算方法においては以下のごとく数値の差と和が定義される。
0+0=0 (これは問題ない)
1+0 = 1 (これもOK)
1-0 = 1 (OK)
0-1 = 1 (?)
0+1 = 1 (No problem)
1+1 =0 (?)
2進法の計算をベースとし、桁あふれや桁たらずを無視して、一桁目だけに着目するわけだ。(だから1+1は10ではなく0になる)そして上の計算式をじっとみるとわかる通り、加算と減算は結果からみれば変わりが無い。
1)前述の前提に従い、送りたい元のデータをM(X)であらわすことにする。(M(X)とはなんだかわからないがXの関数であることを意味する。)一例として送りたいデータを仮に11010111とする。これを多項式で表せば前述の通りX7+X6+X4+X2+X+1である。
2)CRC生成多項式をG(X)であらわす。ここではX3+ X2+1 とする。(これはビット列であらわすと1101だ)そしてG(X)のdegree(これは次数なのかな?)をrとする。(この場合のrは3。1101が4桁だといってr=4ではない。)
3)一気に次の手順を書いてしまうと、
「Xr M(X)をG(X)で割り、その余りをR(X)とする。」
となる。さて、これは具体的に何を意味するか?
まずXr M(X)であるが、素直に多項式の世界で計算すれば、先ほどの例を使うと
X3 M(X) = X10+X9+X7+X5+X4+X3
となる。
これを先ほどとは逆にビット列に直してみると11010111000となり、コンピューター用語では
「ビット列を左にr桁シフトすること」
普通の言葉で言えば、
「r桁分0をくっつけること」
に相当する。(右に3っつ0がついているでしょ)
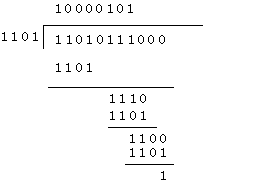
次にこのXr M(X)をG(X) で割る。割り算だから小学生でならった筆算でもって割れば好いのだが、この際引き算には前述のmodulo2を用いる。したがって計算は例えばこうなる。多項式であらわすと
これを元にもどしてビット列で考えると
のようになる。最終的に付与するCRCはrすなわちdegreeと同じ桁数である。この例では3桁であるから、頭に0を二つつけて001となる。
4)送信するデータはXrM(X) - R(X)となる。(本によってはXrM(X) + R(X)と書いてある。前述したとおりmodulo2演算では加算と減算は同じ結果だからこの二つの式の結果は同一である)この場合は
11010111001
となる。最後の3桁がCRCだ。この送信データをT(X)とおこう。
このデータを送信すると、途中でエラーが乗るかもしれない。そのエラーをE(X)としてみよう。となると受信側が受け取るのはT(X)+E(X)のデータだ。
5)一方受信側の処理だが、受け取ったデータ、T(X)+E(X)をG(X)で割ってみる。もし余りが0ならばエラーがなかったことになる。エラーがないということはE(X) =0。であれば、もともとXrM(X)からG(X)で割った余りR(X)を引いて送信しているのだから、割り算の結果余りが0になるのは当然だろう。
もし割った結果余りが生じればそれは通信途中でエラーが生じたことになる。
さて以上がCRCによるエラーチェックの仕組みである。ここからは多少天下り的なCRCの性質の説明をいくつか。
・エラーを検知できない確率は、E(x)がランダムに均一に分布しているとすると(つまりランダムなエラーが発生するとすると)2-rである。(なぜかような値になるかについて、講義で説明があったのだが、忘れてしまった)
・長さがr以下のバーストエラーは検知できる。また長さr以上の多くのバーストエラーも検知できる。
・実際に使われるG(x)には例えば以下のようなものがある
CRC−12:G(x) = X12 + X11 + X3 + X2 + X + 1
CRC-16:G(X) = X16+ X15+X2+1 (HDLCで使用)
CRC-CCITT:G(X) =X16+X12+X5+1
CRC-32:G(x) = x32 + x26+x16+x12+x11+x10+x5+x4+x2+x+1 (Ethernet で使用)
なぜこのようなパターンが選ばれるかについても講義では説明があったが、私が理解できなかったので習わないお経を唱えるのはこれくらいにして置こう。
なおこのように説明すると大変手間がかかる処理に見えるが、ハードで実現するのは実に簡単とのこと。(だから広く使われているのだが)一例としてCRC-CCITTによるCRC付加をハードで行う場合は以下のようになる。
もっとも私はこのハードがどうして前記の計算をしてくれるのか全くわかっていないのでここでは「ふーん。こんなシンプルな回路でできるんだ」と思って次に進んでほしい。
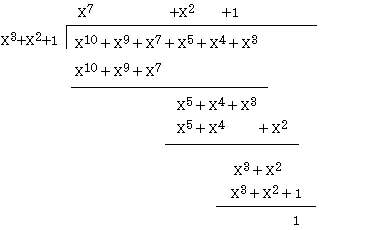

注釈